Welcome to the June 2026 report from the Reproducible Builds project!

In these reports, we outline the most important things that we have been up to over the past month. As a quick recap about what problem our project intends to solve, whilst anyone may inspect the source code of free software for malicious flaws, almost all software is distributed to end users as pre-compiled binaries. The motivation behind the reproducible builds effort is to ensure no flaws have been introduced during this compilation process by promising identical results are always generated from a given source, thus allowing multiple third-parties to come to a consensus on whether a build was compromised or not.
If you are interested in contributing to the project, please visit our Contribute page on our website.
In this month’s report, we cover:
- Only installing reproducible packages with repro-threshold
- Distribution work
- diffoscope development
- From our mailing list…
- Documentation updates
- Patches
- Four new scholarly papers
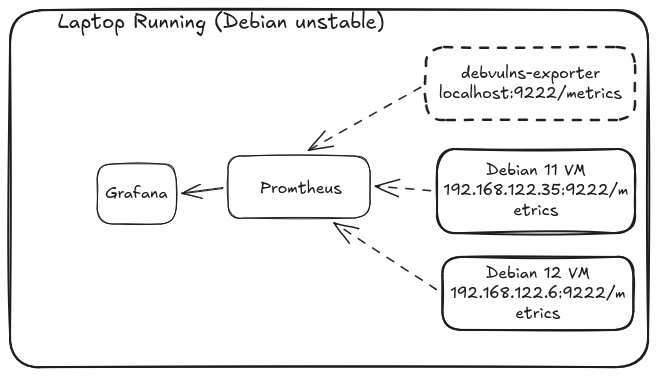
Only installing reproducible packages with repro-threshold

A very interesting demonstration is now available showing how you might configure your Debian system to only install packages that have been reproduced by m/n rebuilders.
This is implemented via a reproduced+https:// APT transport ( a mechanism for communicating between the APT client and its repository source — commonly HTTP):
Every package download is intercepted by repro-threshold, which queries two independent rebuilders for a signed attestation before allowing installation to proceed. [It] is important to note that [an] install will only succeed if all package dependencies are also reproducible.
The demo gives examples of how to quickly experiment with this using a Docker container.
Distribution work

In Debian this month:

The IzzyOnDroid Android APK repository reached its next milestone this month, now covering 2 out of every 3 apps (66.7%) with reproducible builds. Their documentation for debugging and fixing failed builds has steadily grown as well. More clients have picked up showing reproducibility results (e.g. Droid-ify), and Neo Store now can be configured to stick to only reproducible applications. Further, an independent builder has been added to the build farm, increasing the trust level even more as APK builds can have multiple confirmations now.
At the same time, IzzyOnDroid’s rbtlog got several new features. The most outstanding is caching for frequently used resources such as reproducible-apk-tools, command-line tools and NodeJS in order to counter ongoing issues with GitHub availability, while at the same time saving bandwidth and build time. This change also enables some other some smaller enhancements such as being able to configure build timeouts per recipe for those builds running longer than the average, release pattern filtering for update checks or having a field for maintainer notes to shortly summing up e.g. why a reproducible build failed.

Lastly, Bernhard M. Wiedemann posted another openSUSE monthly update for their reproducibility work there.
diffoscope development

diffoscope is our in-depth and content-aware diff utility that can locate and diagnose reproducibility issues. This month, Chris Lamb made the following changes, including preparing and uploading versions 319, 320, 321, 322 and 323 to Debian:
- Debian adds an extra
Flags: line in the output of ocamlobjinfo, so adjust the test for cross-distribution compatibility. […]
- Bump debhelper compatibility level to 14. […]
- Fix compatibility with Ocaml 5.4.1. […]
- Use
--long-form-style arguments when calling apktool in order to support apktool version 3. […]
- Support Androguard version 4 and previous versions at the same time. […]
- Update copyright years. […]
In addition, Jochen Sprickerhof added better header detection for the Sphinx documentation system […], Michael Daniels fixed the tests when run with zipdetails version 4.006 […] and Zbigniew Jędrzejewski-Szmek added a version of the deprecated os.path.commonprefix method […].
In addition, Vagrant Cascadian updated diffoscope in GNU Guix to version 321 and 323.
Chris Lamb also made the following changes to strip-nondeterminism, our tool to remove specific non-deterministic results from a completed build:
- Skip symlinks when manually called via
/usr/bin/strip-nondeterminism. (#1139000)
- Update
debian/watch format. […]
- Drop
Rules-Requires-Root: no and Priority: optional fields. […]
- Bump
Standards-Version to version 4.7.4. […]
From our mailing list…
On our mailing list this month:
-
kpcyrd posted to our mailing list regarding the “waves of malware uploads to aur.archlinux.org”. Curiously, “every incident I looked at used npmjs.com for malware delivery”, specifically where the npm package includes an (automatically executed) preinstall script that is an ELF binary.
-
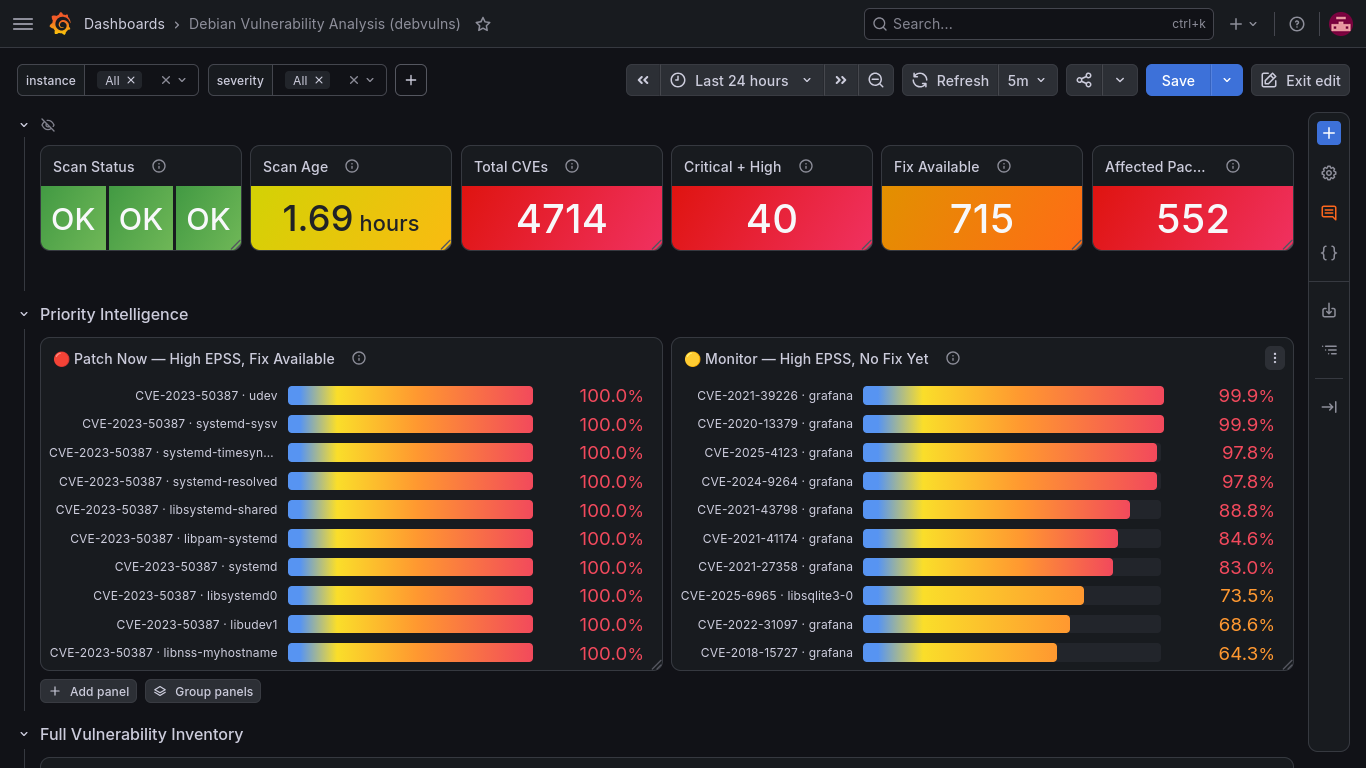
kpcyrd also announced the release of debian-repro-status version 0.4.0, a tool written “to give you an approximate idea of how viable it would be to enforce a ‘reproducible packages only’ update policy for the computer system you’ve built”:
The change updates dependencies to the latest versions, and adds support for multiple -H options, to query results from multiple rebuilderd instances. The results are also now fetched concurrently.
-
kpcyrd also reported that, whilst taking a screenshot for the above release, they noticed that the debian:sid container now is 100% reproducible.
-
Finally, kpcyrd also created a pull request against the add-determinism package to update the itertools and zip Python dependencies.
Documentation updates

Yet again, there were a number of improvements made to our website this month including:
-
Chris Lamb added a reminder re. using the UTC variants of the Javascript Date methods. […]
-
Mattia Rizzolo moved OTF to the ‘old’ sponsors list. Thank you for your support!. […]
-
kpcyrd updated the Rust documentation to recommend using the --release argument for consistency. […]
Patches
The Reproducible Builds project detects, dissects and attempts to fix as many currently-unreproducible packages as possible. We endeavour to send all of our patches upstream where applicable or possible. This month, we wrote a large number of such patches, including:
Four new scholarly papers

Kenichiro Muto and Kuniyasu Suzaki of the Institute of Information Security in Yokohama, Japan published an interesting paper this month titled Attestable Build Chain: Enabling Trust in Reproducible Builds (PDF). Their abstract is as follows:
Ensuring trust in software supply chains requires verifying not only artifacts but also the processes that produce them. Although Reproducible Builds (R-B) require rebuilding to validate artifacts, they cannot verify whether the build was executed with the intended toolchain and inputs and may reproduce unintended or compromised builds without detection. We present Attestable Build Chain, a framework for externally verifying build-time execution without rebuilding. Rather than preventing compromise, it provides verifiable, tamper-evident evidence of actual build-time execution, enabling verification of build process integrity from observed file accesses during the build. […]

Julien Malka, Stefano Zacchiroli and Théo Zimmermann published a 50-page report detailing A Decade of Software Reproducibility in the Nix Package Ecosystem:
We find that functional package management enables extremely high rebuildability over time (near-universal ability to reconstitute historical build environments and rebuild software packages), while bitwise reproducibility has steadily improved and reaches a high point in recent years (up to 93% in 2024). Early years show substantially lower bitwise reproducibility, indicating that functional package management alone does not guarantee bitwise-identical outputs, and that the observed high level of bitwise reproducibility is not solely due to the package management approach. Common causes of unreproducibility, both in the rebuildability and bitwise reproducibility dimensions, include management of dates in build and test processes; we quantify their prevalence and other common causes using manual analysis of logs of rebuild failures and automated analysis of diffoscope.
A PDF of their report is available online

Tim Bastin of L3montree GmbH and Jacek Galowicz of Applicative Systems GmbH from DevGuard published a paper detailing How We Built a Sovereign, Reproducible Container Supply Chain for DevGuard:
This paper presents how the DevGuard project rebuilt its OCI container pipeline around reproducible Nix builds and independent dual-platform digest verification. DevGuard images are built hermetically from pinned source revisions, signed with Sigstore/Cosign, and verified through digest comparison across GitHub Actions and sovereign GitLab infrastructure hosted on container.gov.de. We describe the practical integration of reproducible OCI image builds into existing CI/CD workflows and argue that independently reproducible container digests provide a stronger integrity guarantee against build tampering than provenance alone. The paper further discusses remaining trust assumptions and the relevance of sovereign build infrastructure for government and regulated environments.

Finally, Yiseul Choi, Junga Kim, Jun-Ho Hong and Seongmin Kim of the Department of Convergence Security Engineering at the Sungshin Women’s University in Seoul, Korea titled Attestation-based verification of SBOM integrity via consumer-side reproducibility:
Software bills of materials (SBOMs) support supply chain transparency, but they do not prove that a delivered SBOM reproducibly corresponds to its software artifact. Existing signing and provenance mechanisms protect integrity and traceability, yet lack consumer-side reproducible verification. We propose an SBOM integrity verification framework combining procedure disclosure, consumer-side reproduction, authority-generated reference evidence, and digest comparison. A trusted authority records a reference digest, and consumers compare it with locally reproduced and delivered SBOM digests. Experiments on 100 real-world container images show detection of artifact tampering, SBOM substitution, distribution modification, and adaptive tampering beyond signature-based approaches
Finally, if you are interested in contributing to the Reproducible Builds project, please visit our Contribute page on our website. However, you can get in touch with us via:







 Figure: Renewal relationships between AWS certifications.
Figure: Renewal relationships between AWS certifications.










 July already. Wow. It's getting to be a summer.
July already. Wow. It's getting to be a summer.






